In the era of data-driven insights, automating the extraction, transformation, and loading (ETL) of weather data is essential. This blog takes you through a project that utilizes Apache Airflow, Kafka, Apache Spark Structural Streaming, Cassandra DB, and Trino to seamlessly extract, process, and query weather data for Pondicherry and Melbourne in intervals of every 10 minutes.
High-level architecture diagram:
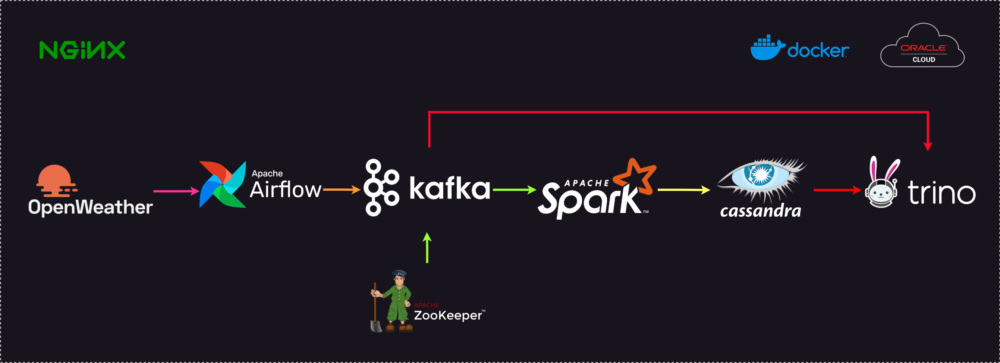
Phase 1: Data Extraction with Airflow
1.1 OpenWeather API Integration
Start by integrating the OpenWeather API with Airflow to fetch weather data for Pondicherry and Melbourne. The JSON structure of the data is as follows:
json
{
"id": "556c12f62222411b8fb1a9363c39087b",
"city": "Pondicherry",
"current_date": "2023-12-31T11:39:56.709790",
"timezone": "b'Asia/Kolkata' b'IST'",
"timezone_difference_to_gmt0": "19800 s",
"current_time": 1704022200,
"coordinates": "12.0°E 79.875°N",
"elevation": "3.0 m asl",
"current_temperature_2m": 27,
"current_relative_humidity_2m": 68,
"current_apparent_temperature": 28.756290435791016,
"current_is_day": 1,
"current_precipitation": 0,
"current_rain": 0,
"current_showers": 0,
"current_snowfall": 0,
"current_weather_code": 1,
"current_cloud_cover": 42,
"current_pressure_msl": 1011.4000244140625,
"current_surface_pressure": 1011.0546875,
"current_wind_speed_10m": 16.485485076904297,
"current_wind_direction_10m": 58.39254379272461,
"current_wind_gusts_10m": 34.91999816894531
}1.2 Airflow Scheduling
Set up an Airflow DAG to schedule the data extraction task every 10 minutes. This ensures a regular and timely flow of weather data into the pipeline.
Phase 2: Streaming to Kafka and Spark
2.1 Kafka Integration
Integrate Kafka into the workflow to act as the intermediary for streaming data between Airflow and Spark. Configure topics for Pondicherry and Melbourne, allowing for organized data flow.

2.2 Spark Structural Streaming
Leverage Apache Spark Structural Streaming to process the JSON data from Kafka in real-time. Implement Spark jobs to handle the incoming weather data and perform any necessary transformations.

Phase 3: Loading into Cassandra DB
3.1 Cassandra Schema Design
Design a Cassandra database schema to accommodate the weather data for both Pondicherry and Melbourne. Consider factors such as partitioning and clustering to optimize queries.
3.2 Cassandra Data Loading
Use Spark to load the processed weather data into Cassandra. Implement a robust mechanism to handle updates and inserts efficiently.

Phase 4: Querying with Trino
4.1 Trino Configuration
Set up Trino (formerly PrestoSQL) to act as the query engine for the data stored in Cassandra and Kafka. Configure connectors for both systems to enable seamless querying.

4.2 Query Examples
Provide examples of Trino queries that showcase the power of querying weather data from both Cassandra and Kafka. Highlight the flexibility and speed of Trino for data exploration.
Conclusion: A Seamless Data Journey
In conclusion, this project demonstrates the power of automation and integration in the data processing realm. By orchestrating data extraction with Airflow, streaming with Kafka and Spark, loading into Cassandra, and querying with Trino, we’ve created a robust and scalable pipeline. This not only ensures a continuous flow of weather data but also enables efficient querying and analysis, unlocking valuable insights for various applications.

