




KinAI Ecosystem: Privacy-First AI for Smarter Family Living
![]()
KinAI — Your Family’s Digital Heart
In a world where smart devices often compromise privacy, the KinAI Ecosystem redefines intelligent living. This AI-powered suite brings enterprise-grade automation to your home, covering healthcare, security, home management, education, and family tracking — all while keeping your data private and secure.
What is KinAI?
KinAI is more than a smart home system; it’s a family-aware AI that understands your loved ones’ routines and needs. Simply ask:
You: “Hey KinAI, how’s everyone doing today?”
And receive a warm, contextual response:
KinAI: “Your daughter arrived home at 5:30 PM, finished her homework, and is watching TV. Your father’s vitals are normal, and Mom’s running 10 minutes late to her appointment.”
KinAI integrates six specialized modules to deliver meaningful insights in milliseconds, acting like a trusted family member.
The KinAI Suite
The KinAI Ecosystem comprises six interconnected, privacy-first projects:
- 🏠 KinAI-Vision: AI-driven home automation that learns your family’s rhythms. Repo

- 🏥 KinAI-CareVault: Securely manages medical records, appointments, and budgets with local LLMs. Repo

- 🛡️ KinAI-NexPatrol: Advanced security with local computer vision and threat detection. Repo

- 📚 KinAI-ScholarKit: Offline, curriculum-aligned educational activity generator. Repo

- 👨🏫 KinAI-Mentor: Voice-driven AI tutor for personalized, offline learning. Repo

- 📍 KinAI-GeoPulse: Privacy-first family tracking with smart geofencing. Repo

KinAI Ecosystem — Seamless Integration for Family Life

Privacy by Design
Unlike cloud-dependent systems, KinAI processes all data locally, ensuring your family’s information stays within your home network. With enterprise-grade encryption, local LLMs (Gemma 3, MedGemma 3), and a Graph RAG architecture, KinAI delivers intelligence without compromising security. No eavesdropping, no data sharing — just pure, private automation.
Why KinAI Stands Out
- Contextual Intelligence: Understands family dynamics, schedules, and cultural nuances.
- Multi-Agent Coordination: Seamlessly integrates data for human-like responses.
- Real-Time Insights: Delivers answers in under 2 seconds, from safety to health updates.
- Open-Source Freedom: Fully transparent, free, and customizable.
A Vision for Smarter Living
Whether ensuring your kids are safe, tracking health metrics, or automating home routines, KinAI transforms raw data into family wisdom. It’s not just about what’s happening — it’s about what it means for your loved ones.
Get Started: Dive into the KinAI Ecosystem on GitHub for setup guides, code, and documentation. Build a smarter, safer home today!
Built with ❤️ for privacy, intelligence, and automation.
Legacy Projects:
Innovating Sustainability: From Solar-Powered Smart Displays to the Modern Data Stack and Beyond
A Fusion of Eco-Friendly Home Automation, Data-Driven Insights, and Automated Weather Forecasts
In the dynamic landscape of technology, this blog unveils a narrative that seamlessly intertwines three captivating stories: the transformation of broken laptops into solar-powered smart displays for sustainable home automation, the exploration of the modern data stack’s capabilities in handling real-world data, and the integration of automated weather forecasts using OpenWeather, Apache Airflow, Apache Kafka, and Telegram. Brace yourself for a comprehensive journey that fuses innovation, sustainability, data-driven insights, and automated weather updates.
Repurposing Broken Laptops for Sustainable Home Automation
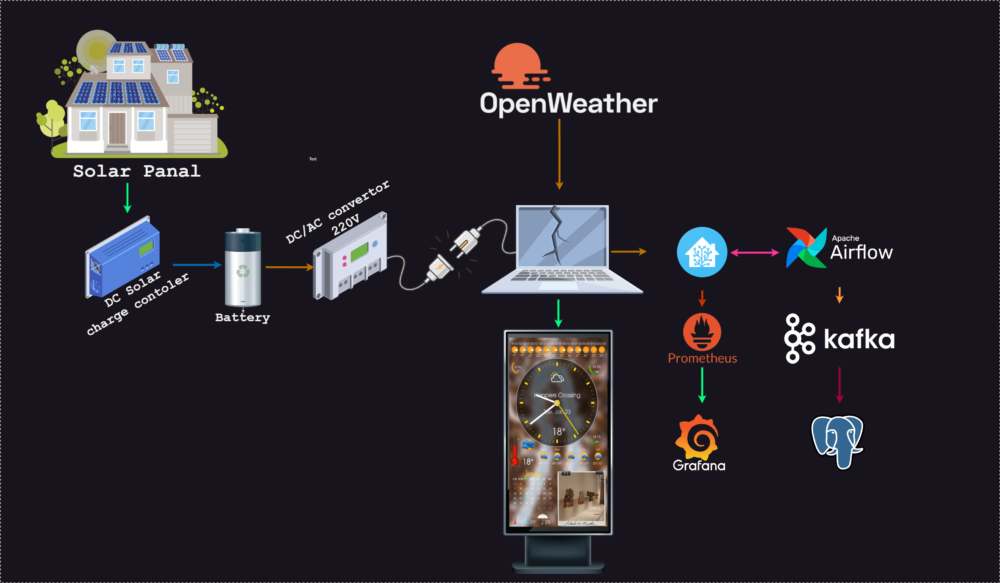
The quest for sustainable living takes a bold step as we delve into repurposing broken laptops into solar-powered smart displays. This initiative goes beyond technical feats, showcasing the potential of eco-friendly innovation. The blog guides readers through the step-by-step process, from installing Home Assistant and transforming a discarded laptop into a smart display to augmenting its functionality with solar energy and battery storage. Witness the resurrection of outdated technology, creating an environmentally conscious and technologically advanced setup for the home.
The Modern Data Stack: Empowering Data-Driven Decisions
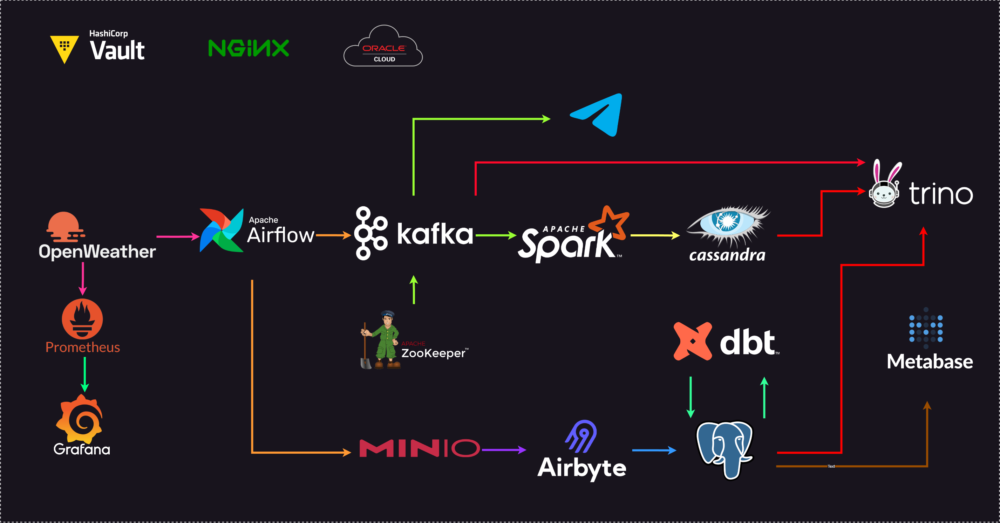
As we embark on this sustainable journey, the spotlight shifts to the modern data stack—an ensemble of integrated tools and processes designed to redefine how organizations handle data. This section introduces participants to the practical aspects of ELT/ETL processes and data modeling, using weather data sourced from the OpenWeather API as a tangible example.
Automated Weather Forecasts with OpenWeather, Apache Airflow, Apache Kafka, and Telegram
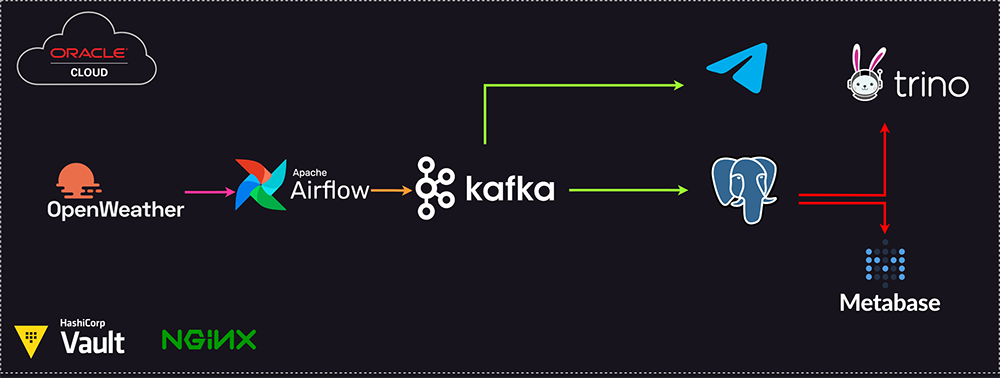
Taking innovation a step further, we introduce the integration of OpenWeather, Apache Airflow, Apache Kafka, and Telegram for automated weather forecasts. Participants engage in a home workshop, leveraging the modern data stack to automate the delivery of daily weather forecasts. The workflow, orchestrated by Apache Airflow, collects weather data from OpenWeather, processes it, and uses Apache Kafka to facilitate seamless communication. Telegram delivers daily forecasts every four hours, from 6 AM to 9 PM, accompanied by a random proverb Thirukural verse for a touch of inspiration.
Bridging Two Worlds: Sustainability, Data Integration, and Automated Forecasting
This synthesis of sustainable home automation, the modern data stack, and automated weather forecasting offers participants a holistic understanding of integrated data processing. The blog underscores the potential of the modern data stack in handling diverse data sources and its role in driving data-informed decision-making. The automated weather forecasts serve as a practical application, showcasing the power of technology in delivering real-time, actionable insights seamlessly.

Conclusion: Harmonizing Sustainability, Data Insights, and Automation
In conclusion, this blog serves as a harmonious convergence of sustainable home automation, the modern data stack, and automated weather forecasting. Through the innovative repurposing of broken laptops, exploration of data processing tools, and integration of automated workflows, participants gain not only technical insights but also a profound appreciation for the symbiotic relationship between innovation, sustainability, data-driven decision-making, and automated processes. It’s a journey that invites individuals to embrace a future where eco-friendly practices, cutting-edge technology, and automated insights coalesce to shape a smarter, greener world.